![[ML] Model Validation](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2Fbetu5Z%2FbtrvAbjiWBx%2FUNcJ1H9GcIHFDOT7gX1210%2Fimg.png)
1. What is Model Validation
대부분의 어플리케이션에서 모델의 성능을 나타내는 척도는 예측 정확도이다. 즉, 모델의 예측값이 얼마나 실제값과 가까운지를 측정하는 것이다. 여기서 사람들이 혼동하는 부분이 훈련데이터에 대해서 예측정확도를 구하는 것이 예측정확도로 알고 있다.
모델 성능을 측정하는데 많은 기법이 있지만 흔히 쓰이는 수식은 평균절대오차 MAEdlek.
error = actual - predicted오차는 실제값과 예측값의 차이를 계산하는데 MAE는 이 값에 절댓값을 씌워 모든 오차를 양의 값으로 변환한 후 평균을 계산한다.
from sklearn.metrics import mean_absolute_error
predicted_home_prices = melbourne_model.predict(X)
mean_absolute_error(y, predicted_home_prices)
2. The Problem with "In-Sample" Score
위와 같은 MAE metrics의 경우 데이터의 훈련 데이터 만을 이용하여 모델의 정확성을 측정하므로, 새로 주어지는 데이터에 대한 정확도를 보장할 수 없다. 가장 빠른 해결 방법은 모델 생성시에 훈련데이터와 평가 데이터를 구분하여 모델의 정확도를 validation dataset을 이용하여 계산하는 방법이다.
3. Coding it
from sklearn.model_selection import train_test_split
# split data into training and validation data, for both features and target
# The split is based on a random number generator. Supplying a numeric value to
# the random_state argument guarantees we get the same split every time we
# run this script.
train_X, val_X, train_y, val_y = train_test_split(X, y, random_state = 0)
# Define model
melbourne_model = DecisionTreeRegressor()
# Fit model
melbourne_model.fit(train_X, train_y)
# get predicted prices on validation data
val_predictions = melbourne_model.predict(val_X)
print(mean_absolute_error(val_y, val_predictions))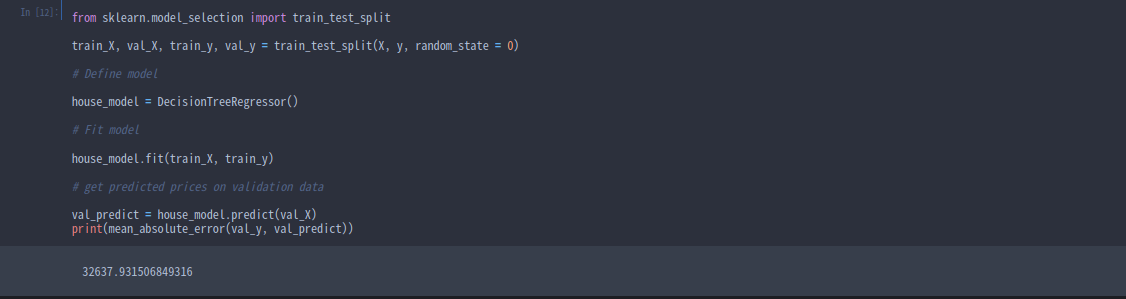
4. Exercise : Model Validation
Step 1 : Split Your Data
# Import the train_test_split function and uncomment
from sklearn.model_selection import train_test_split
# fill in and uncomment
train_X, val_X, train_y, val_y = train_test_split(X, y, random_state = 1)Step 2 : Specify and Fit the Model
# Specify the model
iowa_model = DecisionTreeRegressor(random_state = 1)
# Fit iowa_model with the training data.
iowa_model.fit(train_X, train_y)Step 3 : Make Predictions with Validation Data
# Predict with all validation observations
val_predictions = iowa_model.predict(val_X)Step 4 : Calculate the Mean Absolute Error in Validation Data
# Predict with all validation observations
val_predictions = iowa_model.predict(val_X)Source of the course : Kaggle Course _ Model Validation
'Course > [Kaggle] Data Science' 카테고리의 다른 글
| [ML] Random Forests (0) | 2022.02.14 |
|---|---|
| [ML] Underfitting and Overfitting (0) | 2022.02.14 |
| [ML] Your First Machine Learning Model (0) | 2022.02.14 |
| [ML]Basic Data Exploration (0) | 2022.02.14 |
| [Python] Renaming and Combining (0) | 2022.02.11 |