![[ML] Your First Machine Learning Model](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FnB0nR%2FbtrvvtY2cSL%2FBU2UeAeseIWl2IHZOuUKrk%2Fimg.png)
1. Selecting Data for Modeling
변수나 컬럼을 선택하기 위해 우리는 데이터 셋의 컬럼들을 살펴볼 필요가 있다. 이것은 데이터 프레임의 columns 속성을 통해 확인 가능하다.
import pandas as pd
melbourne_file_path = '../input/melbourne-housing-snapshot/melb_data.csv'
melbourne_data = pd.read_csv(melbourne_file_path)
melbourne_data.columns
# The Melbourne data has some missing values (some houses for which some variables weren't recorded.)
# dropna drops missing values
melbourne_data = melbourne_data.dropna(axis = 0)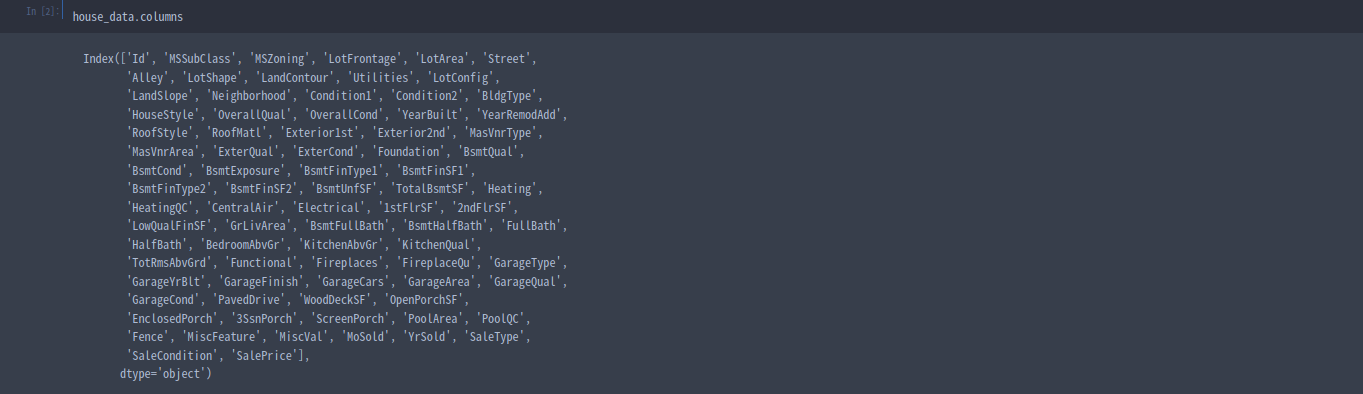
2. Selecting The Prediction Target
우리는 예측하고자 하는 컬럼을 dot notation을 통해 추출하고 이를 예측 타겟으로 부른다. 편의를 위해 대부분의 예측 타겟은 y로 저장한다.
y = melbourne_data.Price
3. Choosing "Features"
우리의 모델 안에서 입력되어지는 컬럼을 'feature(변수)' 라고 부른다. 이 데이터셋의 경우 이 컬럼은 부동산 가격을 예측하는데 사용된다.
melbourne_features = ['Rooms', 'Bathroom', 'Landsize', 'Lattitude', 'Longtitude']
X = melbourne_data[melbourne_features]4. Building Your Model
모델을 생성하기 위해 scikit-learn 라이브러리를 사용한다.
The steps to building and using a model are :
- Define : 어떤 타입의 데이터를 사용할 것인지 정의한다
- Fit : 주어진 데이터에서 패턴을 발견한다
- Predict : 데이터를 예측한다
- Evaluate : 예측한 모델의 정확도를 평가한다.
from sklearn.tree import DecisionTreeRegressor
# Define model. Specify a number for random_state to ensure same results each run
melbourne_model = DecisionTreeRegressor(random_state=1)
# Fit model
melbourne_model.fit(X, y)많은 머신러닝 모델들은 모델 훈련시 우연성을 허용하고 있다. 이 우연성은 동일한 난수를 생성하기위해 random_state라는 parameter를 지정해 준다.
# Make predictions
melbourne_model.predict(X.head())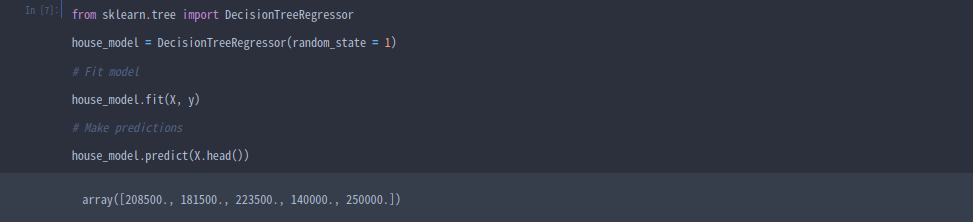
5. Exercise : Your First Machine Learning Model
Step 1 : Specify Prediction Target
# print the list of columns in the dataset to find the name of the prediction target
home_data.columns
y = home_data.SalePriceStep 2 : Create X
# Create the list of features below
feature_names = ['LotArea', 'YearBuilt', '1stFlrSF', '2ndFlrSF', 'FullBath', 'BedroomAbvGr', 'TotRmsAbvGrd']
# Select data corresponding to features in feature_names
X = home_data[feature_names]Step 3 : Specify and Fit Model
from sklearn.tree import DecisionTreeRegressor
#specify the model.
#For model reproducibility, set a numeric value for random_state when specifying the model
iowa_model = DecisionTreeRegressor(random_state = 0)
# Fit the model
iowa_model.fit(X, y)Step 4 : Make Predictions
predictions = iowa_model.predict(X)
print(predictions)Source of the course : Kaggle Course _ Your First Machine Learning Model
'Course > [Kaggle] Data Science' 카테고리의 다른 글
| [ML] Underfitting and Overfitting (0) | 2022.02.14 |
|---|---|
| [ML] Model Validation (0) | 2022.02.14 |
| [ML]Basic Data Exploration (0) | 2022.02.14 |
| [Python] Renaming and Combining (0) | 2022.02.11 |
| [Python] Data Types and Missing Values (0) | 2022.02.11 |