![[ML] Random Forests](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FcGUMPd%2FbtrvwJAzl3g%2FitpWZUcKwspnm3k0Mm7JGK%2Fimg.png)
1. Random Forest
의사결정 나무는 어려운 결정을 요구한다. 깊은 나무의 경우 각각의 값들이 많은 잎들에 의해 분류되어 과대 적합을 일으킬 수 있고, 낮은 나무의 경우 그 반대로 과소적합을 일으킬 수 있다.
랜덤 포레스트는 앙상블 기법중 하나로 많은 나무를 사용하여 각각의 성분에 대해 평균을 계산하여 예측하게 된다. 단일 나무를 생성하여 예측하는 것보다 여러 default parameter를 가진 나무들의 집합은 좀 더 좋은 예측 정확도를 가질 수 있다.
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_absolute_error
forest_model = RandomForestRegressor(random_state=1)
forest_model.fit(train_X, train_y)
melb_preds = forest_model.predict(val_X)
print(mean_absolute_error(val_y, melb_preds))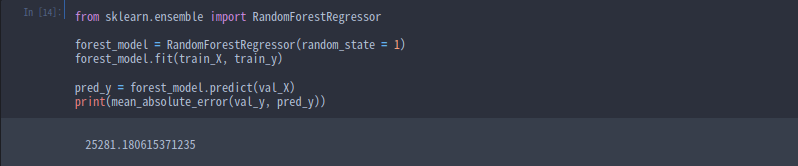
2. Exercise : Random Forests
from sklearn.ensemble import RandomForestRegressor
# Define the model. Set random_state to 1
rf_model = RandomForestRegressor(random_state = 1)
# fit your model
rf_model.fit(train_X, train_y)
# Calculate the mean absolute error of your Random Forest model on the validation data
val_predictions = rf_model.predict(val_X)
rf_val_mae = mean_absolute_error(val_predictions, val_y)
print("Validation MAE for Random Forest Model: {}".format(rf_val_mae))Source of the course : Kaggle Course _ Random Forests
Random Forests
Explore and run machine learning code with Kaggle Notebooks | Using data from multiple data sources
www.kaggle.com
'Course > [Kaggle] Data Science' 카테고리의 다른 글
| [ML] Categorical Variables (0) | 2022.02.19 |
|---|---|
| [ML] Missing Values (0) | 2022.02.19 |
| [ML] Underfitting and Overfitting (0) | 2022.02.14 |
| [ML] Model Validation (0) | 2022.02.14 |
| [ML] Your First Machine Learning Model (0) | 2022.02.14 |