![[DL] Dropout and Batch Normalization](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FcDDfrE%2FbtruQkWUdfI%2FkekMC5mtbEiO29LR36AhgK%2Fimg.png)
1. Dropout
Dense layer에 대해서도 여러가지 종류가 존재하는데 첫번째는 Dropout layer이다. Dropout layer는 과적합(Overfitting)을 방지해주는 효과를 가지고 있다. 기존에 Overfitting을 방지하기 위해 Error함수에 Penalty 함수를 추가하여 Regularization을 수행했다면, Dropout layer는 Neural Network의 Connection을 직접적으로 조작하는 방식이다.
Dropout layer는 각 층의 input unit을 무작위적으로 생략(dropout)하면서 반복적으로 학습을 수행한다. 이를 통해 mini batch가 Overfitting되는 기회를 방지하며 좀 더 빠르게 모델을 학습시킬 수 있다.
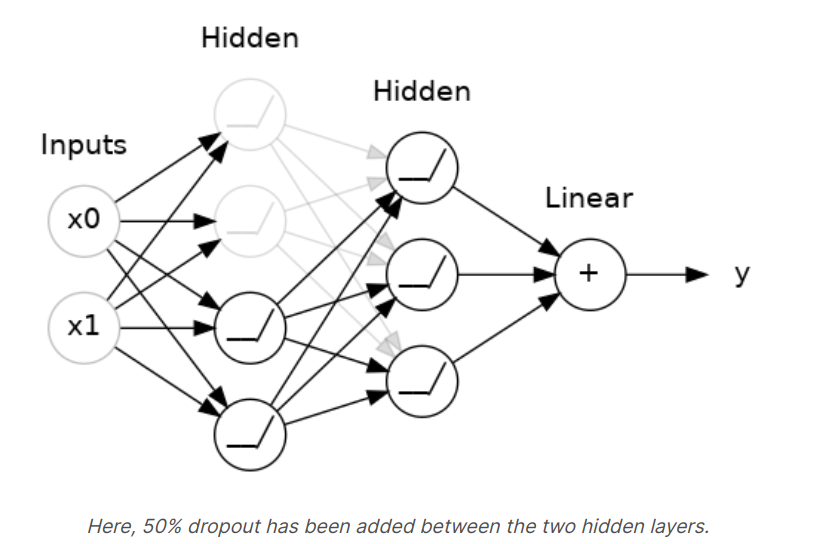
You could also think about dropout as creating a kind of ensemble of networks. The predictions will no longer be made by one big network, but insetad by a committee of smaller networks. Individuals in the committee tend to make different kinds of mistakes, but be right at the same time, making the committee as a whole better than any individual.
3. Adding Dropout
Keras에서는 Dropout() method안에 확률 값 rate 를 지정해주는 방식을 사용한다. Dropout을 적용하고 싶은 층의 입력값(layers.Dnse()) 전에 삽입한다.
Keras.Sequential([
# ...
layers.Dropout(rate = 0.3), # apply 30% dropout to the next lay
layers.Dense(16),
# ...
])4. Batch Normalization
일반적으로 데이터를 전처리한다면 scikit-learn의 StandardScaler, MinMaxScaler를 적용해서 스케일링을 수행한다.
하지만 SGD를 Neural Network에 적용하게 되면, 각 층마다 서로 다른 분포의 입력 데이터를 갖게 된다. Batch 단위 간 데이터 분포가 달라지게 되면 불안정한 훈련을 진행하게 된다(Internal Covariant Shift 문제)
그래서 Batch Normalization은 학습 과정에서 각 Batch 단위 별로 데이터의 분포가 달라지더라도 재 스케일링을 진행하여 평균이 0, 표준편차가 1인 비슷한 분포를 다음 층에 전달할 수 있도록 해준다.
5. Adding Batch Normalization
Dropout과는 다르게 Batch Normalization은 layer의 뒷부분에 넣어 연산을 해준다. 입력층 전에 BatchNormalization을 적용하는 것은 StandardScaler를 적용해 데이터를 입력하는 것과 동일한 과정이다.
layers.Dense(16),
layers.BatchNormalization(),
layers.Activation('relu'),6. Example
from tensorflow import keras
from tensorflow.keras import layers
model = keras.Sequential([
layers.Dense(1024, activation='relu', input_shape=[11]),
layers.Dropout(0.3),
layers.BatchNormalization(),
layers.Dense(1024, activation='relu'),
layers.Dropout(0.3),
layers.BatchNormalization(),
layers.Dense(1024, activation='relu'),
layers.Dropout(0.3),
layers.BatchNormalization(),
layers.Dense(1),
])
model.compile(
optimizer='adam',
loss='mae',
)
history = model.fit(
X_train, y_train,
validation_data=(X_valid, y_valid),
batch_size=256,
epochs=100,
verbose=0,
)
# Show the learning curves
history_df = pd.DataFrame(history.history)
history_df.loc[:, ['loss', 'val_loss']].plot();7. Exercise : Dropout and Batch Normalization
Step 1 : Add Dropout to Spotify Model
# YOUR CODE HERE: Add two 30% dropout layers, one after 128 and one after 64
model = keras.Sequential([
layers.Dense(128, activation='relu', input_shape=input_shape),
layers.Dropout(rate = 0.3),
layers.Dense(64, activation='relu'),
layers.Dropout(rate = 0.3),
layers.Dense(1)
])Step 2 : Add Batch Normalization Layers
# YOUR CODE HERE: Add a BatchNormalization layer before each Dense layer
model = keras.Sequential([
layers.BatchNormalization(input_shape = input_shape),
layers.Dense(512, activation='relu'),
layers.BatchNormalization(),
layers.Dense(512, activation='relu'),
layers.BatchNormalization(),
layers.Dense(512, activation='relu'),
layers.BatchNormalization(),
layers.Dense(1),
])Source of the course : Kaggle Course _ Dropout and Batch Normalization
Dropout and Batch Normalization
Explore and run machine learning code with Kaggle Notebooks | Using data from DL Course Data
www.kaggle.com
'Course > [Kaggle] Data Science' 카테고리의 다른 글
| [DL] The Convolutional Classifier (0) | 2022.03.04 |
|---|---|
| [DL] Binary Classification (0) | 2022.03.02 |
| [DL] Overfitting and Underfitting (0) | 2022.03.01 |
| [DL] Stochastic Gradient Descent (0) | 2022.03.01 |
| [DL] Deep Neural Networks (0) | 2022.02.28 |