![[Python] Creating, Reading and Writing](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FbLaiJS%2FbtrvuO3lNKD%2FEJUMaxLkXPgqCzf7qhiQYk%2Fimg.png)
1. Getting started
판다스 라이브러리를 사용하려면 import ... as 를 사용하여 libary를 호출한다.
import pandas as pd 2. Creating data
판다스에는 두 가지 핵심 객체가 있다 : DataFrame과 Series 이다.
2.1 DataFrame
데이터 프레임 객체는 테이블이다. 각각의 값들에 대한 배열을 형성하며, 행과 열의 구조를 가지고 있다.
pd.DataFrame({'Yes' : [50, 21], 'No' : [131, 2]})
데이터프레임의 각 값은 리스트와 동일하게 다양한 타입의 데이터를 저장할 수 있다.
pd.DataFrame({'Bob' : ['I liked it.', 'It was awful.'], 'Sue' :['Pretty good.', 'Bland.']})
데이터프레임 객체를 생성하기 위해서는 pd.DataFrame() 을 사용하여 만든다. 함수 안에는 딕셔너리 형태로 key는 column 이름을, value는 각 항목의 값을 갖게 된다.
# Assign index name to dataframe
pd.DataFrame({'Bob' : ['I liked it.', 'It was awful.'], 'Sue' : ['Pretty Good', 'Bland.']},
index = ['Product A', 'Product B'])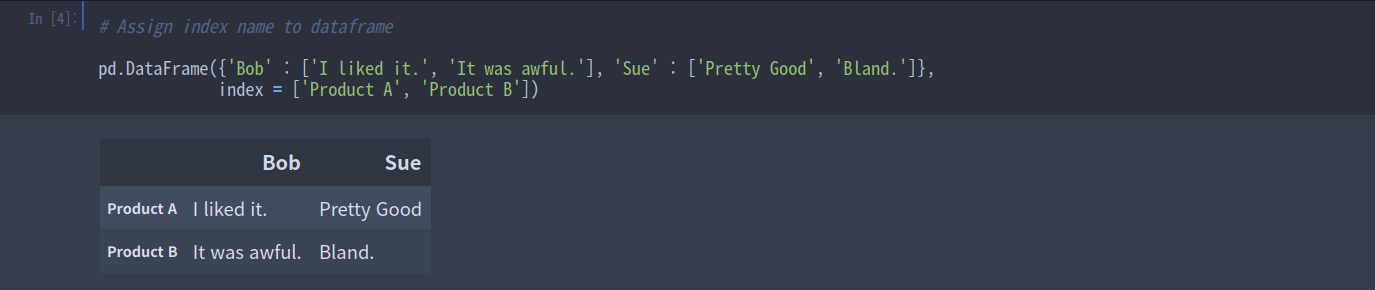
2.2 Series
시리즈(Series)는 반대로 데이터 값의 열이다. 데이터프레임이 테이블이라면(list of list), 시리즈는 list이다.
pd.Series([1, 2, 3, 4, 5])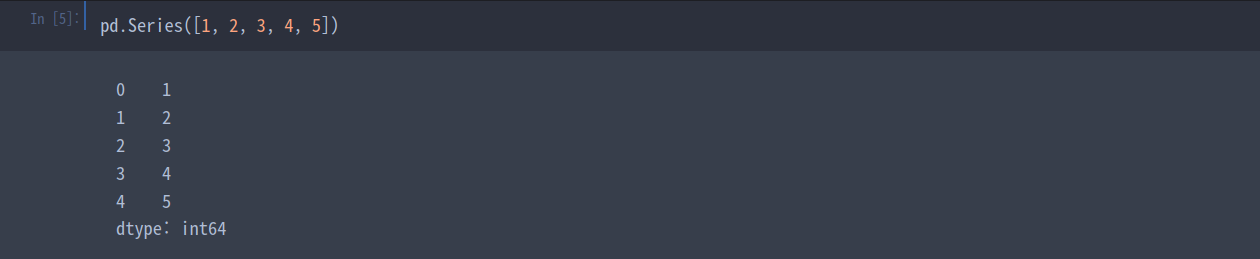
시리즈는 데이터프레임의 한 열을 추출한 형태와 동일하다. 데이터 프레임과 동일하게 행의 이름은 가질 수 있지만, 열의 이름은 가질 수 없고 시리즈 전체의 이름만 가질 수 있다.
pd.Series([30, 35, 40], index = ['2015 sales', '2016 sales', '2017 sales'], name = 'Product A')
3. Reading data files
데이터는 다양한 형식이나 형태로 저장될 수 있다. 가장 흔하게 쓰이는 데이터 형태는 CSV파일이다. CSV파일은 'Comma-Separted values"로 comma에 의해 분리된 파일 형태이다.
# Reading dataframe
wine_reviews = pd.read_csv("../input/wine-reviews/winemag-data-130k-v2.csv")
# method shape : check how large the resulting DataFrame is
wine_reviews.shape
# method head : grabs the first five rows
wine_reviews.head()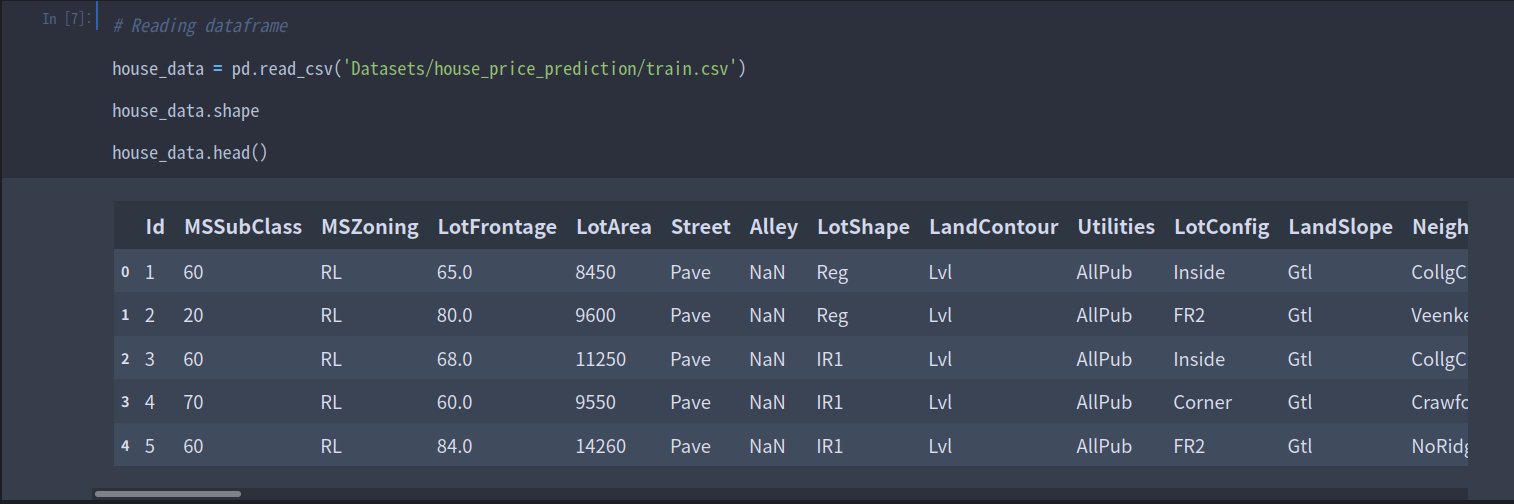
Source of the course : Kaggle Course _ Creating, Reading and Writing
Creating, Reading and Writing
Explore and run machine learning code with Kaggle Notebooks | Using data from multiple data sources
www.kaggle.com
'Course > [Kaggle] Data Science' 카테고리의 다른 글
| [Python] Summary Functions and Maps (0) | 2022.02.11 |
|---|---|
| [Python] Indexing, Selecting & Assigning (0) | 2022.02.11 |
| [Python] Working with External Libraries (0) | 2022.02.11 |
| [Python] Strings and Dictionaries (0) | 2022.02.11 |
| [Python] Loops and List Comprehensions (0) | 2022.02.11 |